前言 Redis 作为一款高性能的内存数据库,凭借其高效、灵活的特性,已成为当下绝大多数项目的核心依赖,广泛应用于缓存、计数、消息队列、地理位置查询等各类场景。
本文整理了 Redis 最常用的 9 种数据类型,每个类型都配实战指令 + 真实业务场景 ,既是入门教程,也是日常开发的速查手册,看完就能直接上手!
一、String(字符串) Redis 最基础、最常用的数据类型,可存储字符串、数字(整数/浮点数)、二进制数据(如图片、序列化对象),最大存储容量为 512MB。核心优势是操作高效,常用于缓存、计数器、分布式锁等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 SET name "zhangsan" SET age 20 EX 3600 SETNX email "test@xxx.com" MSET addr "guangxi" phone "18818868688" GET name MGET name age addr GETRANGE name 0 2 APPEND name "_test" INCR age INCRBY age 5 DECR age DECRBY age 3 DEL name EXPIRE age 60 TTL age PERSIST age
二、Hash(哈希) 用于存储结构化数据(键值对集合),可理解为“字典中的字典”,适合存储用户信息、商品详情等对象类数据。相比 String 存储整个对象(需序列化),Hash 可单独操作对象的某个字段,更灵活、更节省内存。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 HSET user:1 name "lisi" age 25 gender "男" HSETNX user:1 email "lisi@xxx.com" HGET user:1 name HMGET user:1 name age HGETALL user:1 HKEYS user:1 HVALS user:1 HLEN user:1 HINCRBY user:1 age 2 HDEL user:1 gender DEL user:1
三、List(列表) 有序的字符串集合(按插入顺序排序),支持从两端(头部/尾部)添加、删除元素,底层基于双向链表实现,插入/删除效率高,查询效率较低。常用于实现队列、栈、最新消息列表、消息缓冲区等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 LPUSH list1 "a" "b" "c" RPUSH list1 "d" "e" LPUSHX list1 "f" RPUSHX list1 "g" LRANGE list1 0 -1 LRANGE list1 1 3 LLEN list1 LINDEX list1 2 LPOP list1 RPOP list1 LTRIM list1 1 3 DEL list1 BLPOP list2 10 BRPOP list2 10
四、Set(集合) 无序的字符串集合,核心特性是元素唯一 (自动去重),支持交集、并集、差集等集合运算,底层基于哈希表实现,添加、删除、查询效率极高。常用于标签管理、好友关注、抽奖、去重统计等场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 SADD set1 "apple" "banana" "orange" SADD set1 "apple" SMEMBERS set1 SCARD set1 SISMEMBER set1 "banana" SRANDMEMBER set1 SRANDMEMBER set1 2 SREM set1 "orange" SPOP set1 DEL set1 SADD set2 "banana" "grape" "pear" SUNION set1 set2 SINTER set1 set2 SDIFF set1 set2
五、Sorted Set (zset,有序集合) Set 的升级版本,元素唯一且按分数(score)排序 ,底层结合了哈希表和跳表,兼顾了查询、插入效率,支持按排名、分数范围查询。常用于排行榜、优先级队列、带权重的消息排序等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 ZADD player_scores 100 "zhangsan" 95 "lisi" 98 "wangwu" 90 "zhaoliu" 88 "sunqi" 80 "zhouba" ZADD player_scores 60 "wujiu" EXPIRE player_scores 3600 PEXPIREAT player_scores 1770266046000 TTL player_scores PTTL player_scores ZSCORE player_scores "wangwu" ZINCRBY player_scores 10 "wangwu" ZRANGE player_scores 0 2 ZRANGE player_scores 0 2 WITHSCORES ZRANGE player_scores 0 -1 WITHSCORES ZRANK player_scores "zhaoliu" ZREVRANK player_scores "zhaoliu" ZREVRANGE player_scores 0 2 WITHSCORES ZRANGEBYSCORE player_scores 85 100 WITHSCORES ZRANGEBYSCORE player_scores -inf 100 WITHSCORES ZRANGEBYSCORE player_scores (90 100 WITHSCORES ZREVRANGEBYSCORE player_scores 110 90 WITHSCORES ZPOPMIN player_scores ZPOPMAX player_scores BZPOPMIN player_scores 5 BZPOPMAX player_scores 10 ZREM player_scores "lisi" ZREM player_scores "lisi" "wangwu" ZREMRANGEBYSCORE player_scores 0 50 ZREMRANGEBYRANK player_scores 0 2 ZCOUNT player_scores 90 110 ZCARD player_scores ZADD player_scores_2 95 "zhangsan" 92 "lisi" 98 "zhaoliu" ZUNIONSTORE union_scores 2 player_scores player_scores_2 AGGREGATE SUM ZRANGE union_scores 0 -1 WITHSCORES ZINTERSTORE inter_scores 2 player_scores player_scores_2 AGGREGATE MAX ZRANGE inter_scores 0 -1 WITHSCORES ZADD dict_zset 0 "apple" 0 "banana" 0 "cherry" 0 "date" ZLEXCOUNT dict_zset [b (d ZRANGEBYLEX dict_zset [b [c ZSCAN player_scores 0 MATCH "z*" COUNT 5 ZMSCORE player_scores "zhangsan" "lisi" "zhaoliu"
六、Bitmap(位图) 本质是 String 类型的扩展,以“位(bit)”为最小存储单位(每个位仅存储 0 或 1),极致节省内存(1KB 可存储 8192 个状态)。核心用于二值化统计场景,如用户签到、活跃用户标记、在线状态、连续天数统计等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 SETBIT sign:user1 0 1 SETBIT sign:user1 1 0 SETBIT sign:user1 2 1 GETBIT sign:user1 0 GETBIT sign:user1 1 BITCOUNT sign:user1 BITCOUNT sign:user1 0 0 SETBIT sign:user2 0 1 SETBIT sign:user2 2 0 BITOP AND sign:both sign:user1 sign:user2 BITCOUNT sign:both BITPOS sign:user1 1 GET sign:user1
七、HyperLogLog 专门用于基数估算 (统计集合中不重复元素的数量),无需存储具体元素,仅占用固定 12KB 内存,误差率约 0.81%。适合大数据量去重统计场景,如日活(DAU)、访客数(UV)、页面访问去重等,无需精准统计时优先使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 PFCOUNT uv:empty_key PFADD uv:20260225 "user1" "user2" "user3" "user1" "user2" PFCOUNT uv:20260225 PFADD uv:20260225 "user1" "user2" "user3" PFADD uv:20260226 "user3" "user4" "user5" PFMERGE uv:20260225_26 uv:20260225 uv:20260226 PFCOUNT uv:20260225_26 PFADD uv:20260227 "user5" "user6" "user7" PFMERGE uv:20260225_27 uv:20260225 uv:20260226 uv:20260227 PFCOUNT uv:20260225_27 MEMORY USAGE uv:20260225 PFADD page:index:uv:20260225 "user100" "user101" "user100" "user102" "user101" PFCOUNT page:index:uv:20260225 DEL page:index:uv:20260225
八、GEO(地理位置) 用于存储地理位置信息(经纬度),底层基于 Sorted Set 实现,支持距离计算、范围查询、地理位置编码等操作。专为 LBS(基于位置的服务)设计,适合附近的人、门店定位、配送范围查询等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 GEOADD shop:coffee 116.403874 39.914885 "starbucks1" GEOADD shop:coffee 116.410082 39.915072 "starbucks2" GEOADD shop:coffee 116.390604 39.906217 "luckin1" GEOADD shop:coffee 121.473701 31.230416 "starbucks3" 113.264434 23.129110 "starbucks4" GEOPOS shop:coffee "starbucks1" GEODIST shop:coffee "starbucks1" "starbucks2" km GEOSEARCH shop:coffee FROMMEMBER starbucks1 BYRADIUS 1 km ASC COUNT 2 GEOSEARCH shop:coffee FROMLONLAT 116.405285 39.906217 BYRADIUS 1 km ASC COUNT 2 WITHDIST WITHCOORD GEOSEARCH shop:coffee FROMLONLAT 116.4 39.906217 BYBOX 0.5 0.5 km ASC WITHCOORD GEORADIUS shop:coffee 116.403874 39.914885 1 km ASC COUNT 2 GEOHASH shop:coffee "starbucks1" ZREM shop:coffee "luckin1"
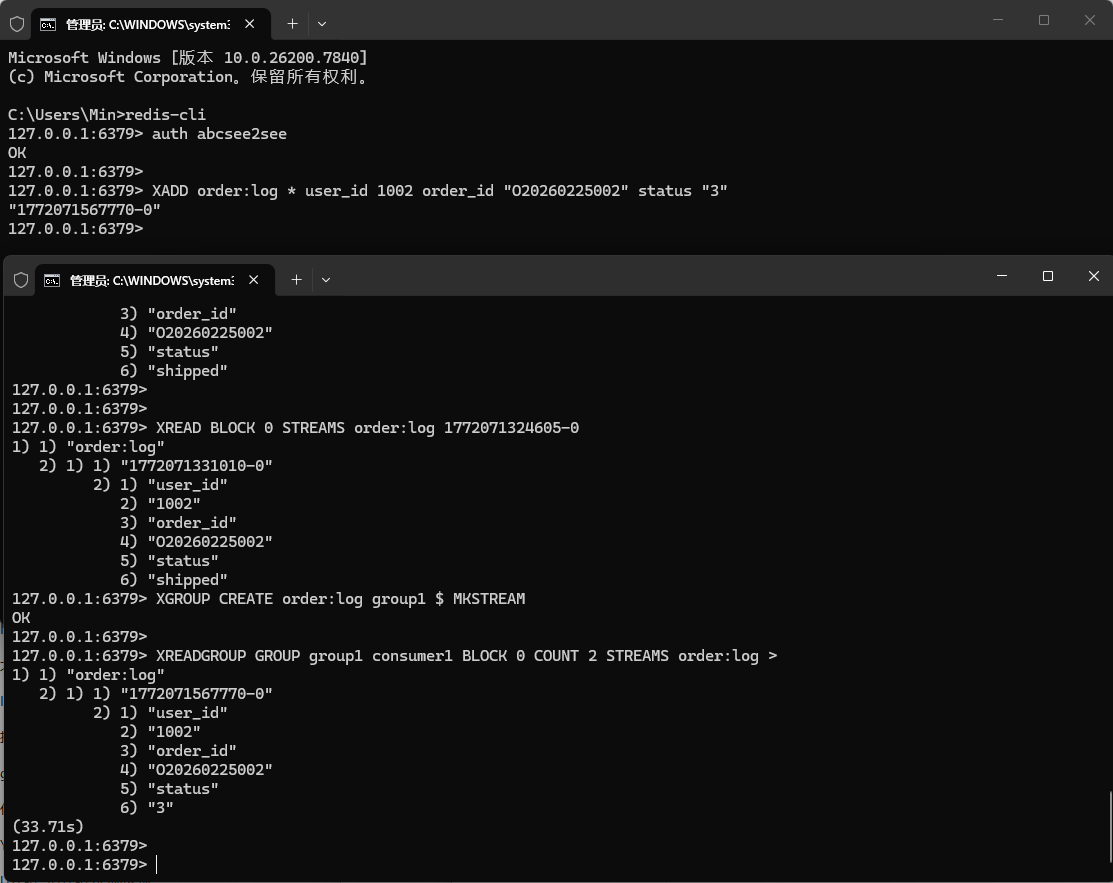
九、Stream(流) Redis 5.0+ 引入的日志型数据类型,支持持久化、消息分区、消费确认、消费组等特性,是 Redis 官方推荐的消息队列实现方式,比 List 更强大、更稳定,适合订单通知、日志收集、异步任务调度等场景。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 XADD order:log MAXLEN ~ 1000 * user_id 1001 order_id "O20260225001" status "paid" XADD order:log * user_id 1002 order_id "O20260225002" status "shipped" XRANGE order:log - + XRANGE order:log - + COUNT 1 XRANGE order:log 1772071300000-0 1773071300000-0 XREVRANGE order:log + - COUNT 1 XREAD BLOCK 0 COUNT 2 STREAMS order:log 0 XREAD BLOCK 0 STREAMS order:log 1772071324605-0 XGROUP CREATE order:log group1 $ MKSTREAM XREADGROUP GROUP group1 consumer1 BLOCK 0 COUNT 2 STREAMS order:log > XACK order:log group1 1772071567770-0 1772071331010-0 1772071324605-0 XLEN order:log XINFO STREAM order:log XINFO GROUPS order:log XDEL order:log 1740460800000-0 DEL order:log
十、最后 根据使用频率和复杂度,我们可以把 Redis 的数据类型分为三个梯队:
第一梯队 (基石型):String, Hash, List, Set, Sorted Set。 这是必须熟练掌握的5种 ,解决了80%的常规需求。**第二梯队 (特种兵型)**:Bitmap, HyperLogLog, GEO。为特定场景(统计、地理)而生,用对地方有奇效。
**第三梯队 (专家型)**:Stream。Redis 官方认证的消息队列方案,适合复杂的流处理场景。
本文所有指令均经过实战验证,可直接复制到Redis客户端执行,方便快速上手落地。
Redis的核心优势在于“按需选型、高效复用”,实际开发中,需结合业务场景的存储需求、查询频率、数据量大小,选择最合适的数据类型,才能充分发挥Redis的高性能优势,同时避免资源浪费。
建议将本文收藏作为速查手册,用到的时候翻出来,效率提升肉眼可见! 滑稽.jpg