1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
| import lombok.RequiredArgsConstructor;
import lombok.SneakyThrows;
import org.springframework.web.bind.annotation.*;
import top.lrshuai.redis.zset.service.PlayerRankService;
import top.lrshuai.redis.zset.vo.R;
import top.lrshuai.redis.zset.vo.RankItem;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.concurrent.*;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/api/rank")
@RequiredArgsConstructor
public class PlayerRankController {
private final PlayerRankService playerRankService;
private final long BATCH_SIZE=10000;
private final long TOTAL=100000000;
private final ThreadLocalRandom random = ThreadLocalRandom.current();
private final ExecutorService executor = new ThreadPoolExecutor(
5,
10,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy()
);
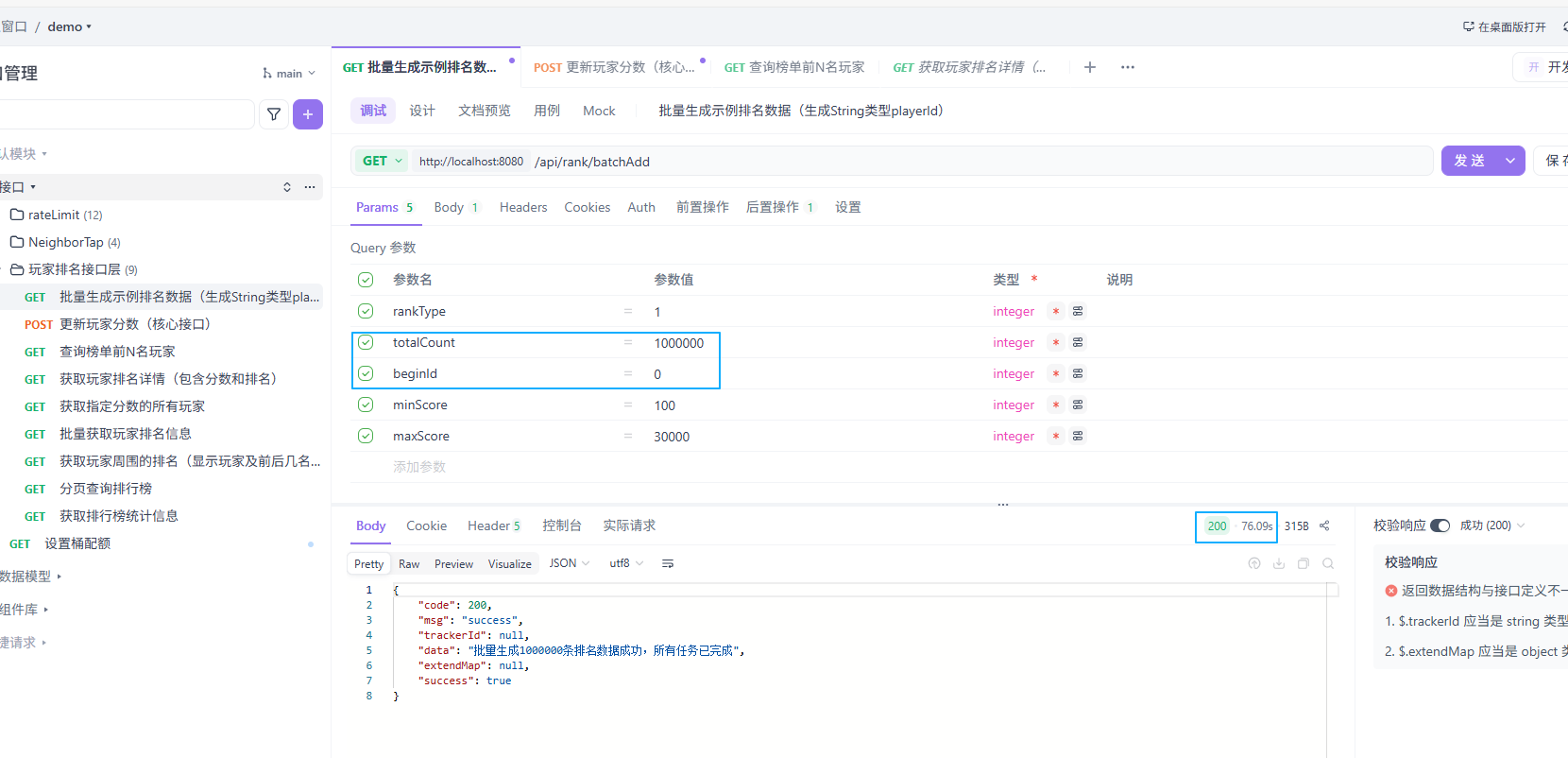
@GetMapping("/batchAdd")
public R<String> batchAddPlayerData(
@RequestParam(defaultValue = "1") int rankType,
@RequestParam(defaultValue = "100") int totalCount,
@RequestParam(defaultValue = "0") long beginId, //从什么用户ID开始
@RequestParam(defaultValue = "100") long minScore,
@RequestParam(defaultValue = "30000") long maxScore) {
try {
if (totalCount <= 0 || minScore > maxScore) {
return R.fail("参数错误:数量需大于0,最小分数不能大于最大分数");
}
long batchNum = totalCount / BATCH_SIZE;
long remainCount = totalCount % BATCH_SIZE;
long updateTime = System.currentTimeMillis();
CountDownLatch latch = new CountDownLatch((int)(batchNum + (remainCount > 0 ? 1 : 0)));
for (long batch = 0; batch < batchNum; batch++) {
long startId = batch * BATCH_SIZE + 1+beginId;
long endId = (batch + 1) * BATCH_SIZE+beginId;
submitBatchTaskWithLatch(rankType, startId, endId, minScore, maxScore, updateTime, latch);
Thread.sleep(100);
}
if (remainCount > 0) {
long startId = batchNum * BATCH_SIZE + 1+beginId;
long endId = batchNum * BATCH_SIZE + remainCount+beginId;
submitBatchTaskWithLatch(rankType, startId, endId, minScore, maxScore, updateTime, latch);
}
boolean allCompleted = latch.await(5, TimeUnit.MINUTES);
if (!allCompleted) {
return R.fail("批量生成任务超时,部分数据可能未完成");
}
return R.ok("批量生成" + totalCount + "条排名数据成功,所有任务已完成");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return R.fail("批量添加被中断:" + e.getMessage());
} catch (Exception e) {
return R.fail("批量添加失败:" + e.getMessage());
}
}
private void submitBatchTaskWithLatch(int rankType, long startId, long endId,
long minScore, long maxScore, long updateTime,
CountDownLatch latch) {
executor.submit(() -> {
try {
for (long i = startId; i <= endId; i++) {
long mainScore = TOTAL-i;
System.out.println("i=" + i + ", mainScore=" + mainScore);
playerRankService.updatePlayerScore(i, rankType, mainScore, updateTime);
}
System.out.println("批次完成:player_" + startId + " ~ player_" + endId);
} catch (Exception e) {
System.err.println("批次插入失败:" + startId + "~" + endId + ",原因:" + e.getMessage());
} finally {
latch.countDown();
}
});
}
@PostMapping("/update")
public R<String> updateScore(
@RequestParam Long playerId,
@RequestParam int rankType,
@RequestParam long mainScore) {
long updateTime = System.currentTimeMillis();
playerRankService.updatePlayerScore(playerId, rankType, mainScore, updateTime);
return R.ok("分数更新成功");
}
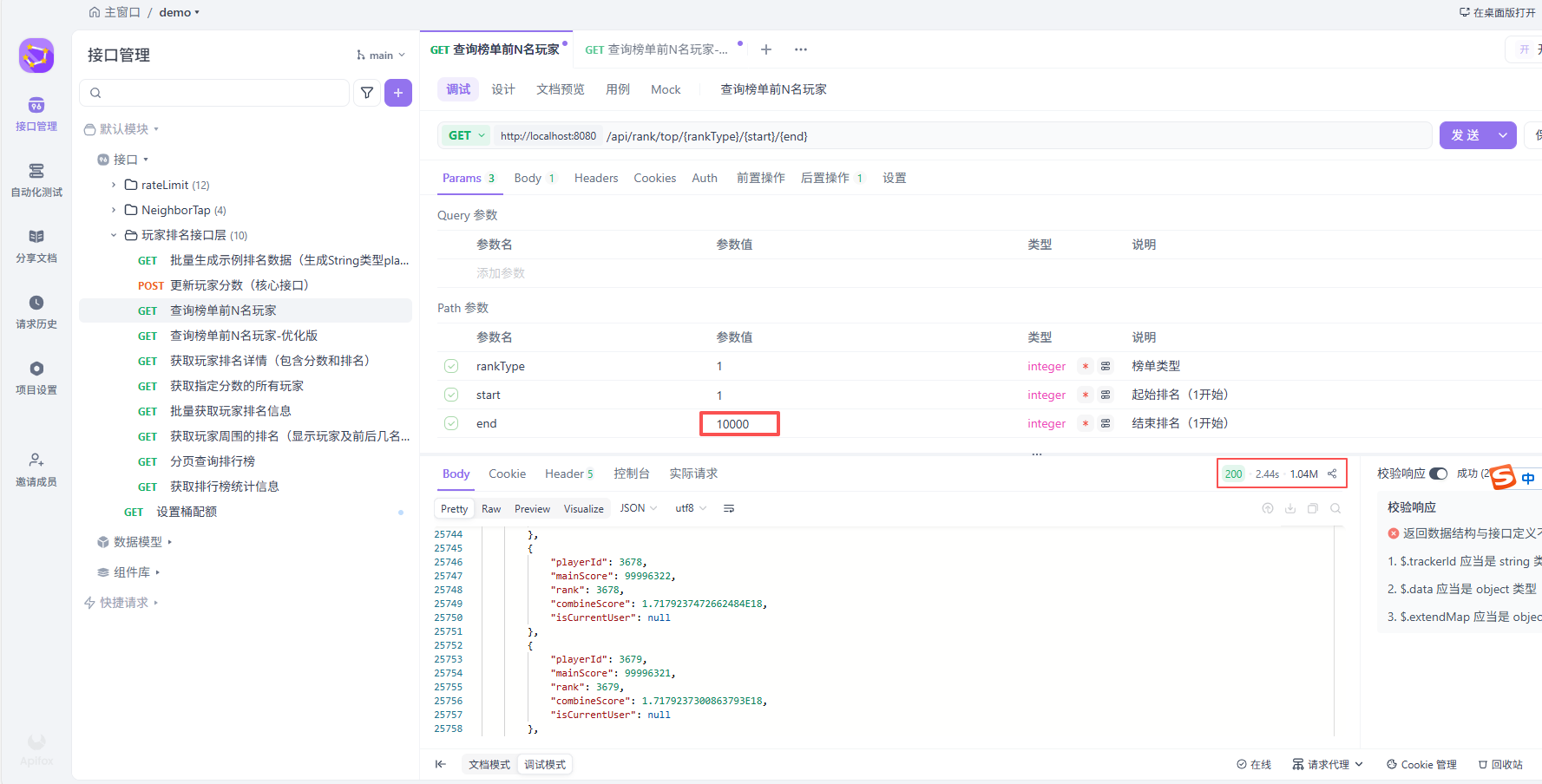
@SneakyThrows
@GetMapping("/top/{rankType}/{start}/{end}")
public R getTopRankList(@PathVariable int rankType, @PathVariable int start, @PathVariable int end) {
return R.ok(playerRankService.getTopRankList(rankType, start, end));
}
@SneakyThrows
@GetMapping("/detail/{rankType}/{playerId}")
public R getPlayerRankDetail(@PathVariable int rankType,
@PathVariable Long playerId) {
RankItem rankDetail = playerRankService.getPlayerRankDetail(playerId, rankType);
if (rankDetail == null) {
return R.fail("玩家不存在或未参与排名");
}
return R.ok(rankDetail);
}
@SneakyThrows
@GetMapping("/players-by-score/{rankType}/{mainScore}")
public R getPlayersByMainScore(@PathVariable int rankType,
@PathVariable long mainScore) {
List<Long> players = playerRankService.getPlayersByMainScore(rankType, mainScore);
return R.ok(players);
}
@SneakyThrows
@GetMapping("/batch-detail/{rankType}")
public R batchGetRankDetails(@PathVariable int rankType,
@RequestParam String playerIds) {
List<Long> idList = Arrays.stream(playerIds.split(",")).map(Long::parseLong).collect(Collectors.toList());
List<RankItem> rankDetails = playerRankService.batchGetRankDetails(idList, rankType);
return R.ok(rankDetails);
}
@SneakyThrows
@GetMapping("/surrounding/{rankType}/{playerId}")
public R getSurroundingRanks(@PathVariable int rankType,
@PathVariable Long playerId,
@RequestParam(defaultValue = "5") int before,
@RequestParam(defaultValue = "5") int after) {
List<RankItem> surrounding = playerRankService.getSurroundingRanks(playerId, rankType, before, after);
return R.ok(surrounding);
}
@SneakyThrows
@GetMapping("/page/{rankType}")
public R getRankByPage(@PathVariable int rankType,
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "20") int pageSize) {
if (page < 1 || pageSize < 1 || pageSize > 1000) {
return R.fail("参数错误:页码需大于0,每页大小在1-1000之间");
}
int start = (page - 1) * pageSize + 1;
int end = page * pageSize;
List<RankItem> rankList = playerRankService.getTopRankList(rankType, start, end);
return R.ok(rankList);
}
@SneakyThrows
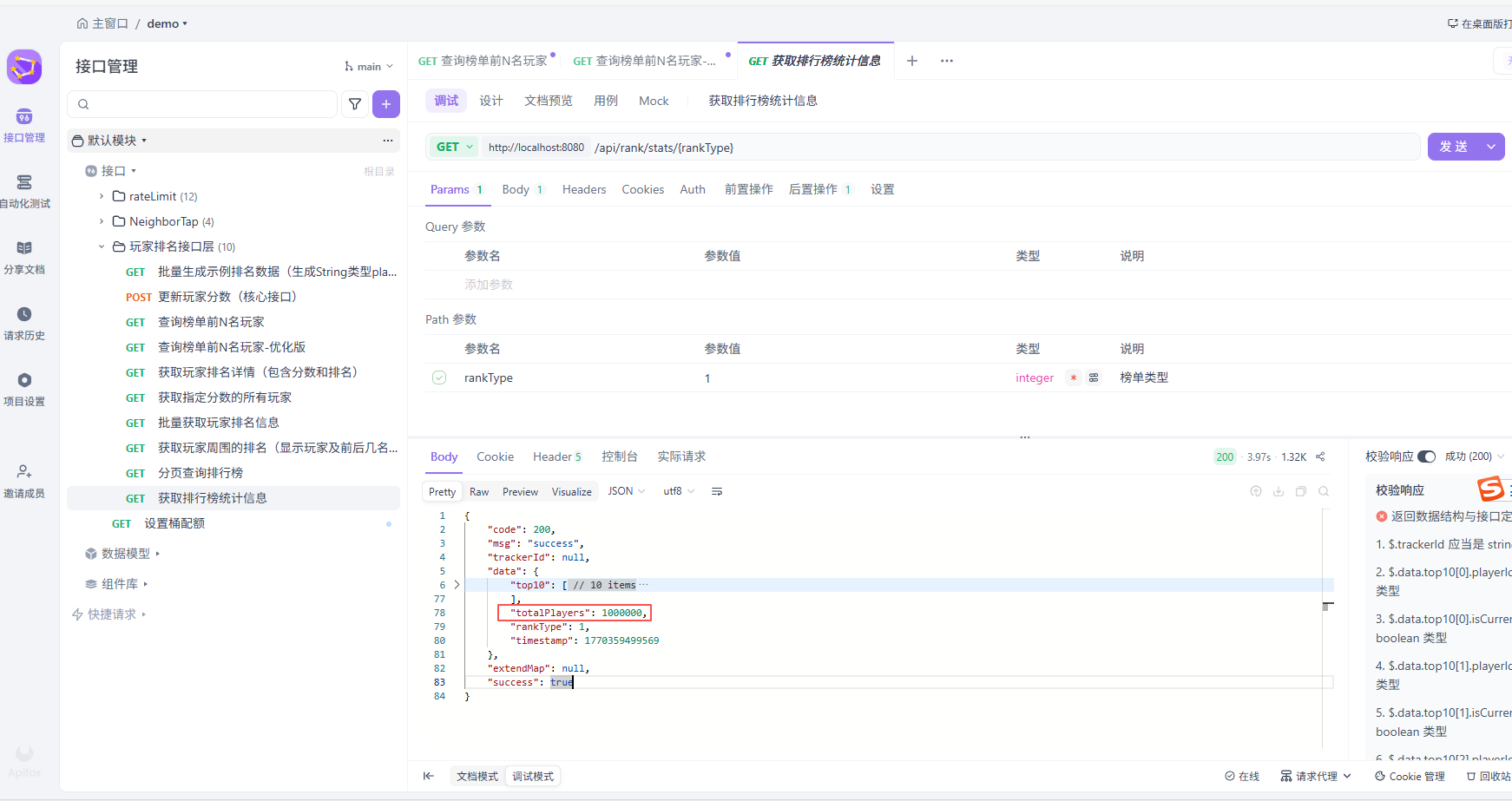
@GetMapping("/stats/{rankType}")
public R getRankStats(@PathVariable int rankType) {
Map<String, Object> stats = new ConcurrentHashMap<>();
stats.put("rankType", rankType);
stats.put("timestamp", System.currentTimeMillis());
List<RankItem> top10 = playerRankService.getTopRankList(rankType, 1, 10);
stats.put("top10", top10);
long totalPlayers = 0;
for (int i = 0; i < playerRankService.getShardCount(); i++) {
String shardKey = playerRankService.getRankKeyPrefix() + rankType + ":" + i;
org.redisson.api.RScoredSortedSet<Long> rankSet = playerRankService.getRedissonClient().getScoredSortedSet(shardKey);
totalPlayers += rankSet.size();
}
stats.put("totalPlayers", totalPlayers);
return R.ok(stats);
}
}
|