一、前言
在单机时代,我们使用Spring的@Scheduled注解稳如老狗。但到了分布式环境,这个“老实人”就变得不可靠了。
核心问题在于:Spring的定时任务调度是每个应用实例独立进行的,它们之间没有通信机制。这就好比一个团队没有项目经理,每个成员都按照自己的理解去完成同一个任务,混乱是必然的。
带来的直接后果:
- 资源浪费:多个实例执行完全相同的任务,消耗宝贵的CPU、内存和数据库连接。
- 数据错乱:核心的数据处理任务被重复执行,导致数据统计不准确,甚至引发业务逻辑错误。
- 服务雪崩:如果任务涉及大量计算或第三方API调用,瞬时多倍的压力可能打垮数据库或外部服务。
面对这些问题,我们必须给这些”各自为政”的定时任务加上统一的”指挥系统”。
二、自研方案:分布式锁注解
如何解决定时任务在集群环境下的重复执行?我们开发一个基于Redis的分布式锁来精准控制。
1、自定义@ScheduledLock 注解
这个注解是我们能力的声明,它告诉我们:“这个定时任务,我需要独占执行!”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface ScheduledLock {
String lockKey();
long holdTime() default 30L;
}
|
设计精髓:
- **
lockKey**:这是锁的灵魂。它必须全局唯一。
- **
holdTime**:这是锁的“保质期”。即使任务执行过程中实例崩溃,Redis也会在超时后自动释放锁,避免了死锁的噩梦。这个时间一定要设置得比任务最大可能执行时间稍长。
2、自定义RedisDistributedLock分布式锁
注解只是外表,真正的力量来源于背后的锁逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| @Component
public class RedisDistributedLock {
@Resource
private StringRedisTemplate stringRedisTemplate;
private static final String LOCK_PREFIX = "scheduled:lock:";
public boolean tryLock(String key, String value, long holdTime) {
String fullKey = LOCK_PREFIX + key;
Boolean success = stringRedisTemplate.opsForValue().setIfAbsent(fullKey, value, Duration.ofSeconds(holdTime));
return Boolean.TRUE.equals(success);
}
public void unlock(String key, String value) {
String fullKey = LOCK_PREFIX + key;
String currentValue = stringRedisTemplate.opsForValue().get(fullKey);
if (Objects.equals(value, currentValue)) {
stringRedisTemplate.delete(fullKey);
}
}
public String generateLockValue() {
try {
String ip = InetAddress.getLocalHost().getHostAddress();
long pid = ProcessHandle.current().pid();
long threadId = Thread.currentThread().getId();
return String.format("%s:%d:%d", ip, pid, threadId);
} catch (Exception e) {
return UUID.randomUUID().toString();
}
}
}
|
代码解析:
tryLock方法:我们使用了Redis的 SET key value NX EX seconds 命令。这个操作的原子性是基石,它确保了“判断是否存在”和“设置值与超时”两个动作一气呵成,避免了并发场景下的竞态条件。unlock方法:这是最容易出错的地方。为什么不能直接delete?想象一下:任务A持有锁,但执行时间超过了holdTime,锁自动释放。此时任务B获得了锁并开始执行。如果这时任务A执行完毕,直接调用delete,就会把任务B的锁给删了!所以,我们必须验证value,确保“锁是自己加的”。generateLockValue方法:我们生成了一个包含IP:PID:ThreadID的复杂标识,几乎可以保证全局唯一。这比使用简单的UUID或时间戳更能清晰地告诉我们,到底是集群中的哪个节点、哪个进程、哪个线程持有了锁,对于后期排查问题至关重要。
3、任务调度ScheduledLockAspect 切面
AOP(面向切面编程)它将分布式锁的逻辑与业务逻辑完美解耦。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| @Slf4j
@Aspect
@Component
public class ScheduledLockAspect {
@Resource
private RedisDistributedLock redisDistributedLock;
@Around("@annotation(scheduledLock)")
public Object aroundAdvice(ProceedingJoinPoint joinPoint, ScheduledLock scheduledLock) throws Throwable {
String lockKey = scheduledLock.lockKey();
long holdTime = scheduledLock.holdTime();
String lockValue = redisDistributedLock.generateLockValue();
boolean isLockAcquired = false;
try {
isLockAcquired = redisDistributedLock.tryLock(lockKey, lockValue, holdTime);
if (!isLockAcquired) {
log.warn("【定时任务锁】获取锁失败,任务即将跳过。lockKey: {}", lockKey);
return null;
}
log.info("【定时任务锁】成功获取锁,开始执行任务。lockKey: {}, lockValue: {}", lockKey, lockValue);
return joinPoint.proceed();
} finally {
if (isLockAcquired) {
try {
redisDistributedLock.unlock(lockKey, lockValue);
log.info("【定时任务锁】任务执行完毕,锁已释放。lockKey: {}", lockKey);
} catch (Exception e) {
log.error("【定时任务锁】释放锁时发生异常。lockKey: " + lockKey, e);
}
}
}
}
}
|
代码执行流程:
- 前置增强:在目标定时任务方法执行前,尝试获取分布式锁。
- 短路逻辑:如果获取失败,直接记录日志并返回,任务被“跳过”。
- 执行原逻辑:如果获取成功,则放心地执行原有的定时任务逻辑。
- 后置增强:在
finally块中,确保锁一定会被释放,避免资源泄漏
4、实战演练
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Slf4j
@Component
public class CustomDemoTask {
@Scheduled(fixedDelay = 30000, initialDelay = 1000)
@ScheduledLock(lockKey = "task:checkOrderTimeout")
public void checkOrderTimeout() throws InterruptedException {
log.info("【超时订单检测任务】开始执行...,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
log.info("【超时订单检测任务】检测中...,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
Thread.sleep(30000);
log.info("【超时订单检测任务】执行完毕。,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
}
}
|
代码解读:
- 在
checkOrderTimeout方法上,我们同时使用了@Scheduled和@ScheduledLock。
lockKey是一个明确的字符串,所有实例上的这个任务都会竞争同一把锁。holdTime, 没设置,默认为30秒,这个值设置为大于你预估任务的执行时间,不然设置太短,锁释放了,会被其他实例重复执行。
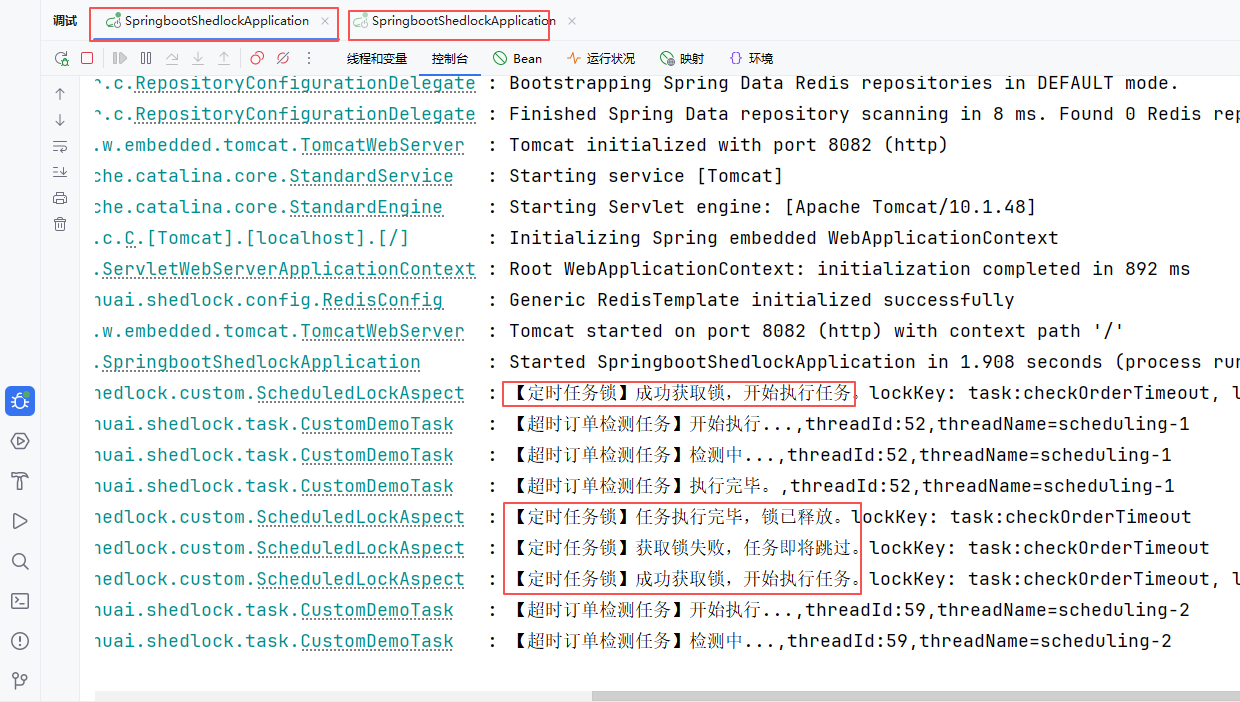
可以看到我们通过不同的端口,启动不同2个实例,如果定时任务被其他实例运行了,那其他实例就不会再次运行了,自此我们已经实现了,分布式集群部署我们就可以实现只有一台实例运行定时任务。
三、拥抱开源
自研的轮子跑起来了,感觉很好。但作为一个有经验的开发者,我们必须思考:这个轮子够稳固吗?它能应对所有复杂的边缘情况吗?
自研方案的潜在陷阱:
- 锁续期问题:如果任务执行时间超过了
holdTime怎么办?自研方案中,锁会自动释放,另一个实例会拿到锁并执行,导致任务再次重复。你需要实现复杂的“看门狗”机制来续期。
- Redis高可用:如果Redis是单点,它挂了整个系统就瘫痪了。你需要考虑Redis哨兵或集群模式下的兼容性。
- 错误处理:网络抖动导致获取锁失败,是否应该重试?重试策略如何?
- 性能与监控:缺乏开箱即用的监控指标,锁的竞争情况不易察觉。
这时,我们就可以考虑使用开源的轮子:ShedLock。Github地址:https://github.com/lukas-krecan/ShedLock
ShedLock的几大优势:
- 成熟稳定:经过大量生产环境验证,社区活跃,有完善的文档和问题解决方案
- 多存储支持:支持MySQL、Redis、MongoDB、ZooKeeper等多种存储后端
- 开箱即用:配置简单,与Spring生态完美集成,几乎零编码
- 完善的容错机制:内置锁超时、自动释放等机制,防止死锁
1、引入ShedLock
在你的pom.xml中添加依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-spring</artifactId>
<version>${shedlock.version}</version>
</dependency>
<dependency>
<groupId>net.javacrumbs.shedlock</groupId>
<artifactId>shedlock-provider-redis-spring</artifactId>
<version>${shedlock.version}</version>
</dependency>
|
2、配置ShedLock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Configuration
@EnableSchedulerLock(defaultLockAtMostFor = "30m")
public class ShedlockConfig {
@Bean
public LockProvider lockProvider(RedisConnectionFactory connectionFactory) {
return new RedisLockProvider.Builder(connectionFactory)
.keyPrefix("task-lock")
.build();
}
}
|
3、快速使用
1
2
3
4
5
6
7
8
9
10
11
12
13
| @Slf4j
@Component
public class ShedLockDemoTask {
@Scheduled(fixedDelay = 5000, initialDelay = 1000)
@SchedulerLock(name = "checkOrderTimeout",lockAtMostFor = "1m",lockAtLeastFor = "10s")
public void shedLockCheckOrderTimeout() throws InterruptedException {
log.info("【ShedLockDemoTask】开始执行...,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
log.info("【ShedLockDemoTask】执行中...,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
Thread.sleep(30000);
log.info("【ShedLockDemoTask】执行完毕。,threadId:{},threadName={}", Thread.currentThread().getId(),Thread.currentThread().getName());
}
}
|
@SchedulerLock注解参数解析:
- **
name**:锁的唯一标识
- 必须全局唯一,通常使用任务方法名
- 支持SpEL表达式,可以实现动态任务名
- 不同任务必须使用不同的name
- **
lockAtMostFor**:锁的最大持有时间
- 作用:防止任务执行过程中应用崩溃导致死锁
- 设置原则:略大于任务正常执行的最大时间
- 示例:任务通常执行5-8分钟,设置为10分钟
- **
lockAtLeastFor**:锁的最小持有时间
- 作用:防止任务执行过快导致多个实例同时获取锁
- 适用场景:高频任务或执行时间很短的任务
- 示例:每10秒执行的任务,设置最小持有时间8秒
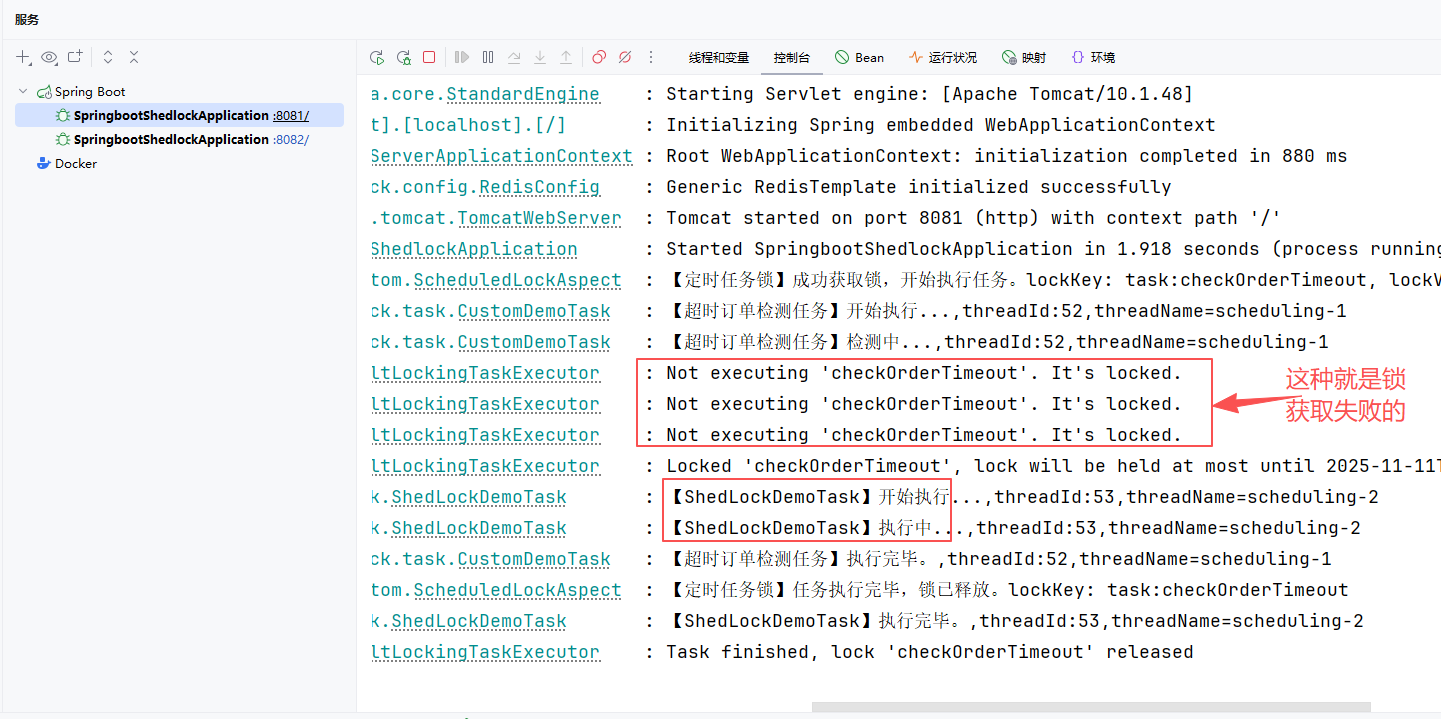
ShedLock底层也是使用AOP切面的。
四、总结
从自研分布式锁到拥抱开源ShedLock。无论选择哪条路径,核心目标都是一致的:在分布式环境下确保定时任务的精确执行。
关键收获:
- 理解分布式锁的核心原理和实现要点
- 掌握AOP在解决横切关注点中的应用
- 学会根据团队和项目情况做出合理的技术选型
在技术选型的道路上,没有绝对的银弹。最重要的是根据实际业务场景、团队技术储备和运维能力,选择最适合的解决方案。
思考题:在你的业务场景中,还有哪些可以通过分布式锁解决的并发问题?欢迎在评论区分享你的实战经验!

