一、前言
最近几年人工智能技术正以前所未有的速度渗透到各行各业。自2020年OpenAI发布GPT-3以来,大语言模型(LLM)引领了新一轮AI浪潮。国内外科技巨头纷纷投身自研大模型的竞争,随着模型能力的不断成熟,AI功能已从单一的文本交互演进为多模态智能体系,最终催生出形态多样的AI智能体应用。
这些AI智能体的底层核心仍然依托于传统的大语言模型,但通过集成工具调用、RAG上下文增强、记忆机制等能力,结合智能化的工作流程,实现了任务的精准拆解和资源的高效协调,从而为用户提供更加精准的结果。
工具调用突破了LLM纯文本处理的局限,使其能够连接现实世界的系统和服务,为AI智能体的发展奠定了坚实基础。
为了更好地理解这一技术体系,我们可以用这样一个比喻:
- AI大模型:如同一位学识渊博但记忆模糊的天才学者
- 它通过海量数据训练获得强大的理解、推理和生成能力
- 但存在两个固有缺陷:知识存在时效限制,无法获取训练后的新信息;可能产生看似合理实则错误的“幻觉”回答
- Prompt(提示词):是与这位天才学者沟通的桥梁
- 提示词的质量直接决定回答的精准度
- 它是用户与大模型交互的核心接口
- RAG(检索增强生成):如同为学者配备的一位专业的图书馆员
- 当提出问题时,检索系统会从专属知识库中快速定位相关信息
- 将这些信息与原始问题整合成增强提示词,确保回答的准确性和时效性
- 知识库存储:就是那个组织有序的私人图书馆,存储着经过结构化处理的专有知识,是RAG流程的坚实基础
知识库存储在RAG中的核心地位
RAG上下文增强技术有效解决了“LLM知识盲区”的问题,其核心在于信息的精准获取与智能融合,通过构建AI可理解的向量知识库,为大模型提供可靠的参考依据。
而其中,知识库存储 作为RAG(检索增强生成)技术的核心环节,对于打造真正“智能”的应用至关重要
Spring AI提供了一套完整的知识库存储解决方案,将文档处理、向量化和存储流程标准化,使开发者能够专注于业务逻辑而非底层技术实现。通过将私有文档转化为AI可理解的结构化知识,企业可以构建真正理解自身业务的专业AI助手。
二、快速开始
在开始之前,先了解一下什么是向量数据库。
向量数据库
1、什么是向量数据库?
简单来说,向量数据库是一种专门用于存储、管理和检索向量(Vector)的数据库,在人工智能应用中发挥着至关重要的作用。
在向量数据库中,查询与传统的关系数据库不同。 他们执行相似性搜索,而不是完全匹配。 当给定向量作为查询时,向量数据库返回与查询向量“相似”的向量。
为了更好地理解,我们先分解几个核心概念:
向量(Vector): 在人工智能和机器学习领域,向量是一组数字的有序列表,通常被称为“嵌入向量”(Embedding Vector)。它可以被理解为在高维空间中的一个点。
例如: 一个单词“猫”,通过一个AI模型(如Word2Vec、BERT)可以转化为一个由512个数字组成的向量,例如
[0.12, -0.45, 0.78, ..., 0.92]。这个向量就代表了“猫”这个词在高维空间中的语义和特征。简而言之,向量是由 N 个数字(在二值向量中为 N 个比特)组成的序列,也称为 N 维向量。而向量检索则是指从一个给定的向量数据集中,按照某种相似性度量,找出与查询向量最接近的 K 个向量,即 K-最近邻(K-Nearest Neighbor, KNN) 搜索。由于 KNN 的计算开销较大,实际应用中更常关注近似最近邻(Approximate Nearest Neighbor, ANN) 问题。
近似最近邻(ANN)是一种在高维空间中牺牲少量精度以换取巨大效率提升的技术.。
嵌入(Embedding): 将非结构化数据(如文本、图像、音频、视频)通过AI模型转换成向量的过程,就叫“嵌入”。这个转换过程能够捕捉原始数据的深层语义和特征。
- 文本 -> 转化为代表其含义的向量。
- 图片 -> 转化为代表其视觉内容(物体、颜色、风格)的向量。
- 音频 -> 转化为代表其声音特征(音调、音色、说话人)的向量。
高维空间(High-Dimensional Space): 想象一个三维空间,我们可以用(x, y, z)坐标定位一个点。向量数据库处理的是几百甚至几千维的空间。在这个空间里,语义或特征相似的向量会彼此靠近。
- 例如:“猫”和“狗”的向量距离,会比“猫”和“汽车”的向量距离要近得多。
因此,向量数据库的核心任务就是:高效地在这个海量的高维向量空间中找到与目标向量最“相似”的向量。
2、常见的向量度量方式
常用的向量相似性度量包括欧氏距离、余弦相似度、曼哈顿距离和点积等。
欧几里得度量(Euclidean Distance):通常称为欧氏距离,指在 m 维空间中两点之间的真实距离,或向量的自然长度(即该向量到原点的距离)。在二维和三维空间中,欧氏距离即为直观的两点间直线距离。
余弦距离:也称为余弦相似度。一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似
曼哈顿距离:也称为城市街区距离,计算各坐标轴上的绝对差之和。公式为:Σ|a_i - b_i|。 得名于在网格状道路的城市中两点间的行走距离
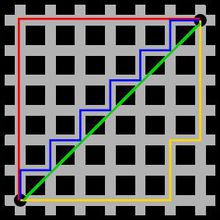
- 图中红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。曼哈顿距离,两点在南北方向上的距离加上在东西方向上的距离
点积 是一种代数运算,用于两个向量之间。对于两个维度相同的向量
A = [a1, a2, a3, ..., an]和B = [b1, b2, b3, ..., bn],它们的点积计算公式为:a·b=a1b1+a2b2+……+anbn。可以把它理解为:将两个向量每个维度上的数值“对齐相乘”,然后将所有乘积结果加起来,得到一个单一的标量数值。- 这个计算出来的标量数值,越大说明越相似,因为当两个向量的方向大致相同时(即指向相似的“方向”),对应维度上的正负号更可能一致,正数乘正数、负数乘负数会得到更多的正值,从而点积结果更大。
- 举个例子:想象两个向量代表顾客的购物偏好。
- 向量 A:
[2, 3](2份喜欢汉堡,3份喜欢薯条) - 向量 B:
[3, 2](3份喜欢汉堡,2份喜欢薯条) - 点积
A·B = 2*3 + 3*2 = 6 + 6 = 12,这个值“12”就量化了他们的喜好相似度。如果来个顾客 C,偏好是[-1, -1](讨厌汉堡和薯条),那么A·C = 2*(-1) + 3*(-1) = -5,这个负值表明他们的喜好是相反的

实战
前面铺垫那么多理论知识,现在我们怎么来用呢?,上面说过了,Spring AI提供了一套完整的知识库存储解决方案,它提供了一套抽象接口,主要依赖是:
1 | <dependency> |
但是我们在使用的时候其实不需要引入这个依赖,只需要引入它的实现依赖即可,实现依赖中已包含了这个依赖
通过抽象接口
VectorStore就可以与向量数据库进行交互,允许我们,添加、删除、搜索向量数据库中的文档。上面是接口还是得实现,但是Spring AI 已经提供了常见向量数据库的各种实现包,如:Chroma、Elasticsearch、Milvus、Redis、PGvector…等等还有好多我都没用过的。
下面来尝试Redis和PGvector 这2个向量数据库,这个
Redis可不是我们本来的Redis,而是扩展之后的 Redis Stack 集成RediSearch、RedisJSON、RedisGraph等等好多模块,而PGvector也是基于PostgreSQL扩展的。为了方便,直接使用docker安装Redis Stack 和PGvector ,下面是我的
docker-compose.yml配置文件
1 | name: vector-env |
- 启动命令:
docker-compose up -d
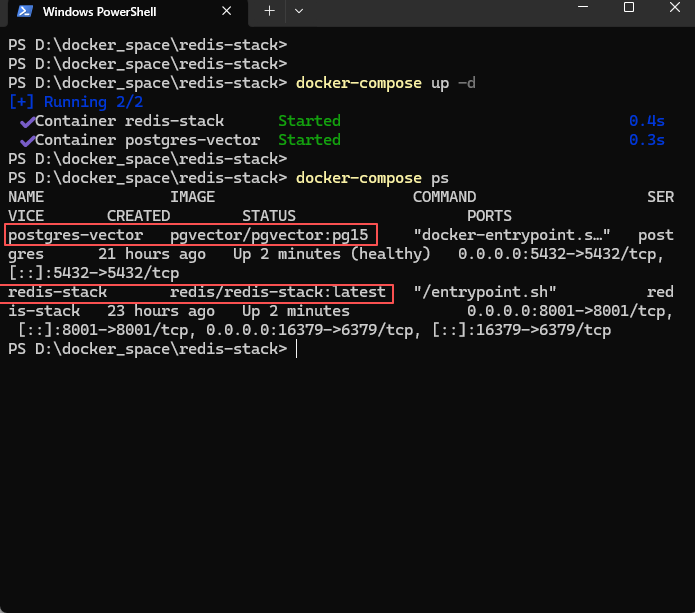
- 直接把redis-stack 和 pgvector 都启动了
1、PGvector
- 我们来试试PGvector向量库,我们只需导入依赖:
1 | <!-- 提供接口测试用 --> |
- 向量数据库的实现主要引入:
spring-ai-starter-vector-store-pgvector就行,因为我们要配置一个嵌入模型把文本转为向量,我这里使用的是ollama本地的方式,有条件可以使用 OpenAI、阿里Qwen等 其他厂商提供的嵌入模型。 - 下面是我的配置文件:
1 | server: |
- 我这里选择的嵌入模型是ollama 部署的
bge-m3模型,pgsql的配置和docker-compose.yml配置文件一样
还有一些配置可自行参考官方文档:https://docs.spring.io/spring-ai/reference/1.1/api/vectordbs/pgvector.html
- 接下来我们新建一个control,试试接口调用,操作向量数据库
1 |
|
如上,我们添加了3个接口,分别是 添加文档、检索文档、删除文档
PGvector,的
VectorStore默认实现类就是:**PgVectorStore** 我们直接使用就行而
filterDuplicateDocuments(List<Document> newDocuments)方法可以不要,我是为了测试去重使用的,因为这个方法会把每个文档的内容去查库里有没有存在,比较影响性能,小知识库直接全删了,再重新加载会好一点,这里为了测试而已。准备工作搞定,我们就可以启动应用来测试接口了。
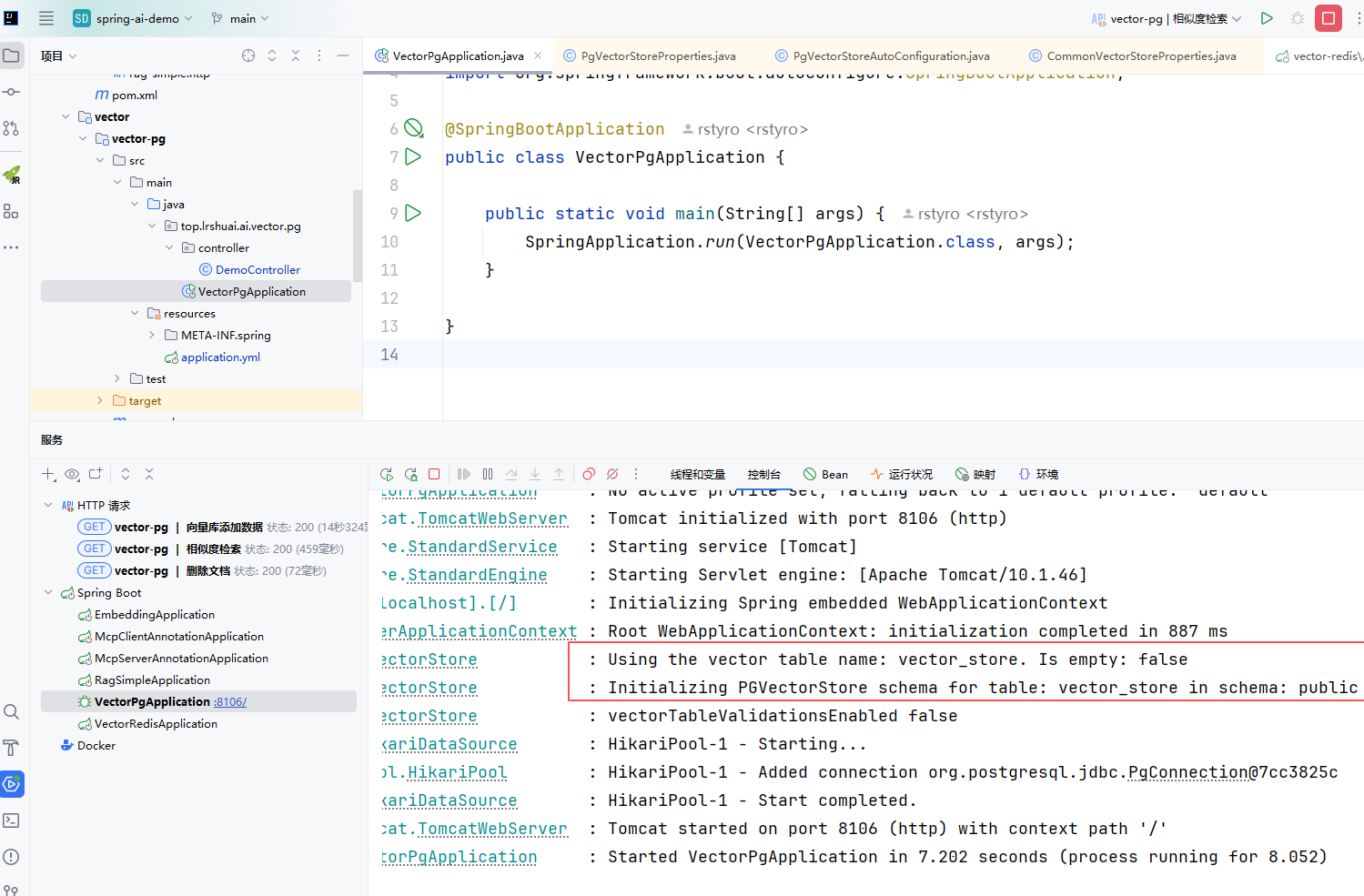
- 看日志我们已经连接成功,默认的数据库表名为:
vector_store,配置,spring.ai.vectorstore.pgvector.initialize-schema=true会自动帮我们新建数据库表 - 当我们请求:
http://127.0.0.1:8106/vectorPg/add接口,会往向量数据库,添加12条星座数据,如下图:
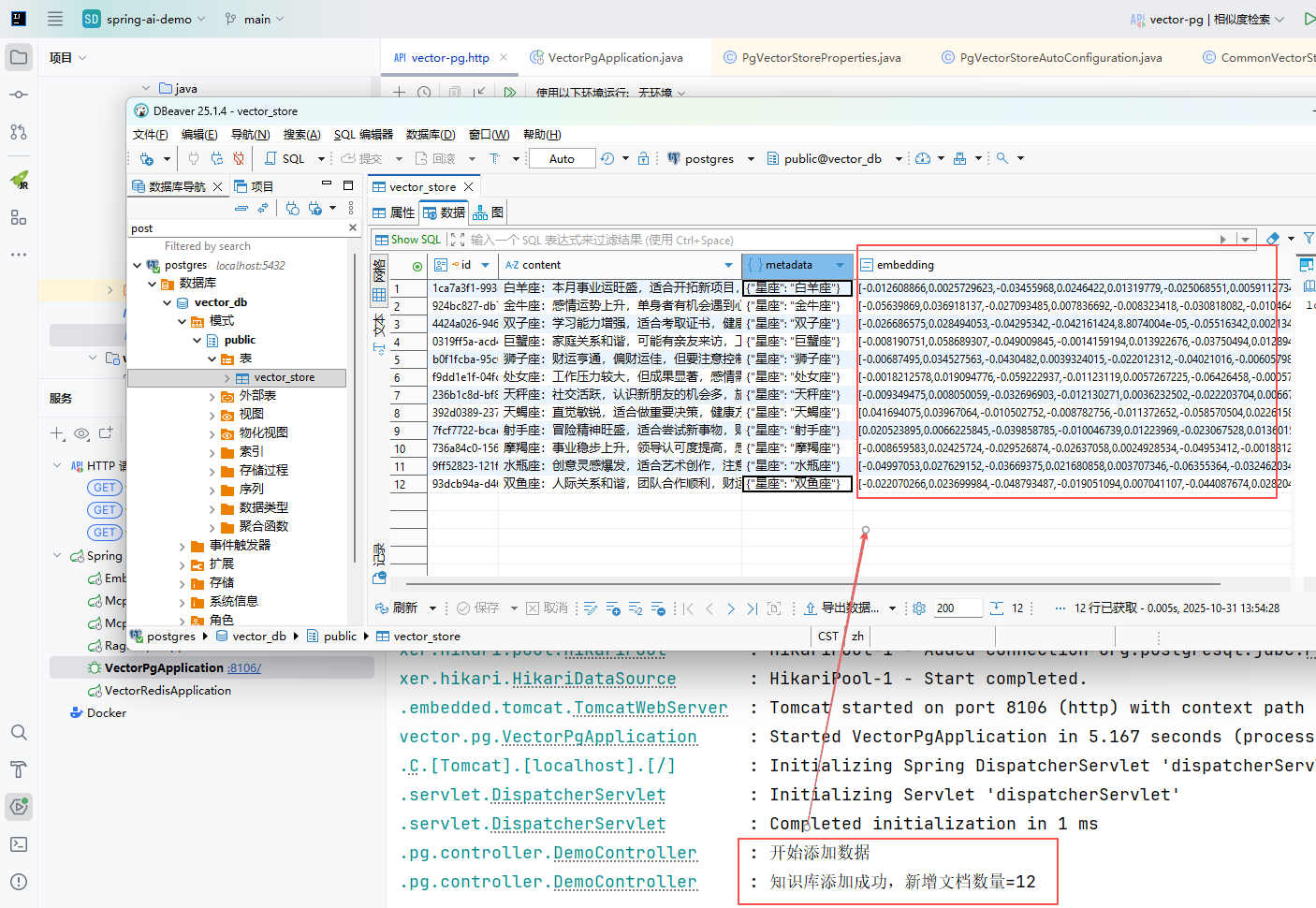
当我们通过查询文字去检索(底层会把文档转为向量再去检索),它会返回文档的相似度得分及文档文本。
查询文字转向量代码如下:
1
2
3
4private PGvector getQueryEmbedding(String query) {
float[] embedding = this.embeddingModel.embed(query);
return new PGvector(embedding);
}在 PgVectorStore.class 可以看到
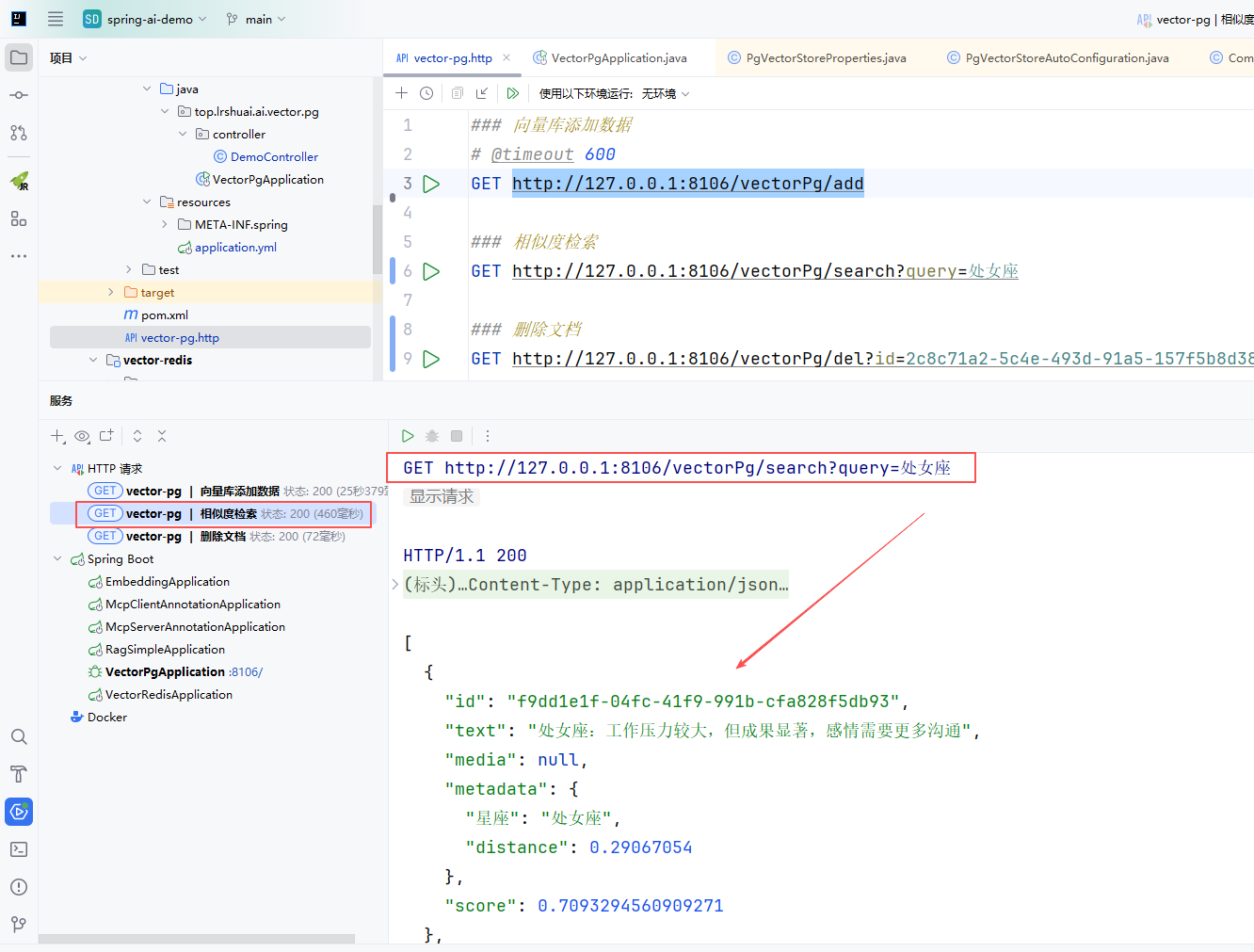
- 可以看到检索会返回文档对应的ID,可以相似度检索分数
- 剩余的删除接口就不截图了,通过检索接口得到的ID就可以删除文档
2、Redis
Redis的向量数据库使用和Pgvector基本一致,把实现包由:
spring-ai-starter-vector-store-pgvector改为spring-ai-starter-vector-store-redis,还有就是VectorStore的实现类,改为使用RedisVectorStore。配置文件改为如下:
1 | server: |
- Controller 内容基本不变,调用add方法后可以在Redis中查询到向量数据:
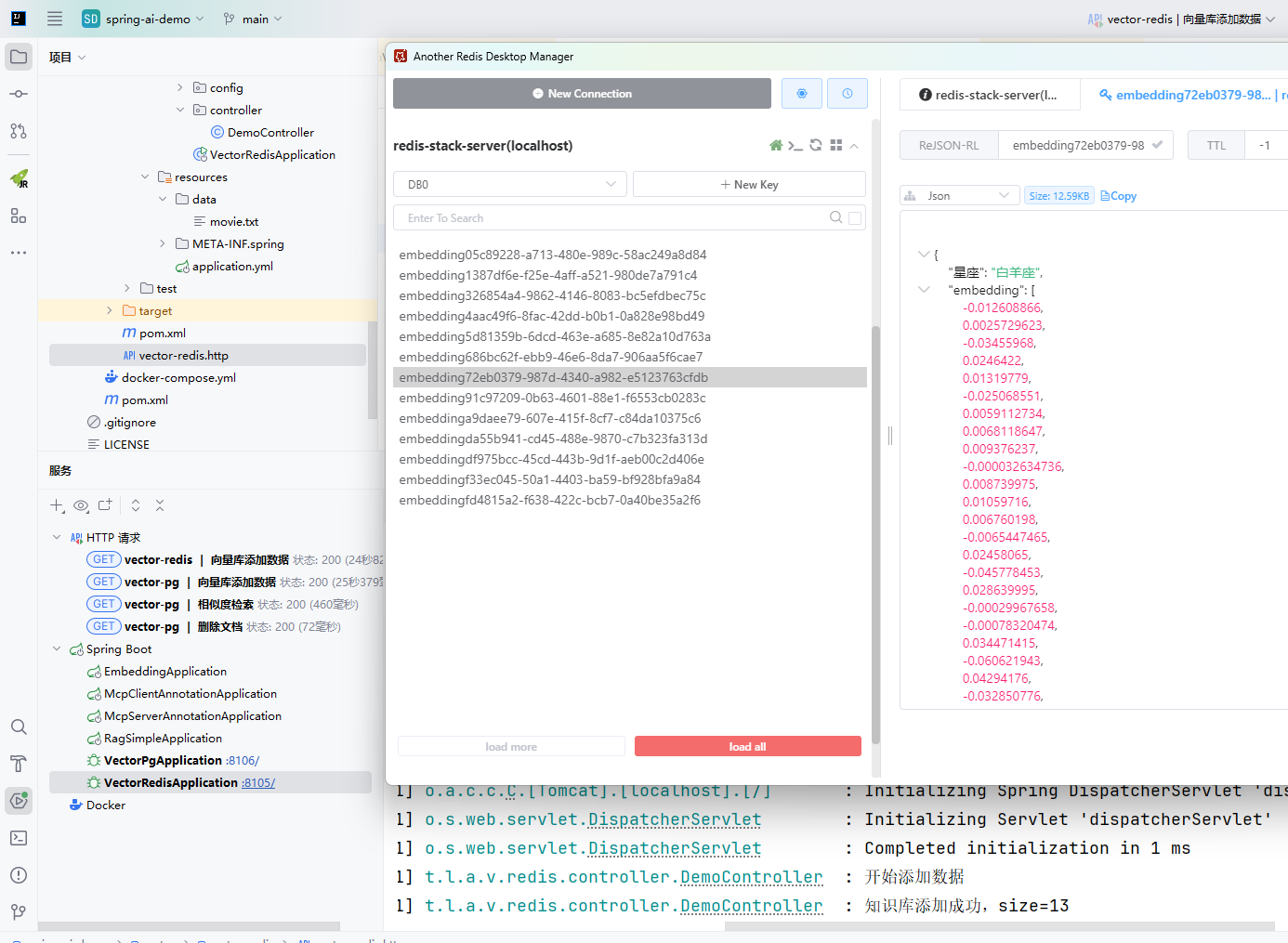
- 其他向量数据库的使用用法基本一致,感兴趣的同学可自定测试其他的向量数据库。
三、总结
通过本文的讲解和实战演示,相信大家对Spring AI搭建RAG知识库有了更深入的理解。让我们来做个全面的总结:
技术要点回顾
- 向量数据库作为RAG体系的核心组件,专门用于处理非结构化数据,通过高效的相似性搜索算法,为大规模知识检索提供了坚实的技术基础
- Spring AI的抽象化API设计极大地降低了向量数据库的使用门槛,使开发者能够快速构建企业级AI应用
- 统一接口的多数据库支持让我们可以在PGvector、Redis等不同向量数据库间灵活切换,大大提升了开发效率和系统可扩展性。随着AI技术的快速发展,掌握RAG和向量数据库技术将成为开发者的重要技能。
未来展望
未来,随着多模态大模型的发展,向量数据库将需要处理更多类型的数据,包括图像、视频、音频等非文本数据,这将进一步拓展RAG技术的应用边界,为人工智能在各行各业的深度应用奠定坚实基础。
资源获取:
本文完整代码已上传至 GitHub,欢迎 Star ⭐ 和 Fork: https://github.com/rstyro/spring-ai-demo
欢迎分享你的经验:
在实际使用Spring AI构建RAG系统时,你有哪些独到的见解或踩坑经验?欢迎在评论区交流讨论,让我们一起进步

