一、前言 Elasticsearch 也是支持脚本查询的。像查询的时候,有时简单的字段排序已经不满足我们的需求了,也可以使用脚本自定义表达式排序。
二、准备环境 先把索引和数据这些准备好。
1、创建索引 创建people索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 PUT http://172.16.1.236:9201/people { "settings": { "number_of_shards": 3, "number_of_replicas": 0 }, "mappings": { "properties": { "id": { "type": "long" }, "name": { "type": "keyword" }, "age":{ "type":"long" }, "info": { "term_vector": "with_positions_offsets", "search_analyzer": "ik_smart", "type": "text", "analyzer": "ik_max_word" }, "job":{ "type":"keyword" }, "asset":{ "type":"double" }, "birthday":{ "type":"date", "format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss.SSS || yyyy-MM-dd || epoch_millis" }, "update_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss.SSS || yyyy-MM-dd || epoch_millis" }, "create_time": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd'T'HH:mm:ss.SSS || yyyy-MM-dd || epoch_millis" } } } }
简单的定义几个字段
2、加入数据 这里使用bulk api 批量导入数据
1 2 3 4 5 6 7 8 9 10 11 PUT http://172.16.1.236:9201/people/_bulk?pretty {"index":{ "_id":"1"}} {"age":20,"asset":1800.88,"birthday":"2000-10-13","create_time":"2020-10-13 09:52:59","id":1,"info":"我就是我不一样的烟火!!!","job":"打工仔","name":"张三","update_time":"2020-10-13 09:52:59"} {"index":{ "_id":"2"}} {"age":20,"asset":2000.88,"birthday":"2001-10-13","create_time":"2020-10-13 09:52:59","id":2,"info":"不要站在你的角度看我我怕你看不懂!!!","job":"打工仔","name":"李四","update_time":"2020-10-13 09:52:59"} {"index":{ "_id":"3"}} {"age":27,"asset":3888,"birthday":"1993-10-13","create_time":"2020-10-13 19:52:59","id":3,"info":"他人喜欢旅游,我喜欢梦游!!!","job":"工程师","name":"王五","update_time":"2020-10-13 09:52:59"} {"index":{ "_id":"4"}} {"age":27,"asset":18888,"birthday":"1993-10-13","create_time":"2020-10-13 19:52:59","id":4,"info":"只要肯努力,想要的都能自己得到!!!","job":"经理","name":"赵六","update_time":"2020-10-13 09:52:59"}
我这里使用的是postman导入的。
这里要注意一点就是postman在Headers 那里要设置 Content-Type:application/json。
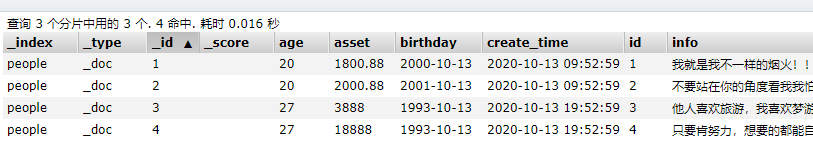
导入之后,查看一下:
三、Script使用 本篇主题,ES默认使用的脚本语言是:Painless,还有可以使用:Lucene expression、mustache 都是内置的。
1、格式: 1 2 3 4 5 "script": { "lang": "...", "source" | "id": "...", "params": { ... } }
脚本的格式基本都是上面这样的,属性解析:
lang: 脚本的语言,默认painless
source: 也就是脚本的内容是 inline script ,也可以为id,这个id不是文档的id,而是stored script的ID。stored script就是我们已经定义好的脚本,下面有讲到。
params: 这个是存参数的对象
2、stored script 直接翻译过来就是脚本存储,简单的说我们先把脚本模板定义好,下次直接引用即可
定义stored 脚本 1 2 3 4 5 6 7 8 PUT http://172.16.1.236:9201/_scripts/add_asset { "script": { "lang": "painless", "source": "ctx._source.asset += params.value" } }
定义一个叫做 add_asset 的stored script,内容的意思就是给资产(asset) 加上参数的值。
使用stored脚本 1 2 3 4 5 6 7 8 9 POST http://172.16.1.236:9201/people/_doc/1/_update { "script": { "id": "add_asset", "params": { "value": 100 } } }
这里script里面的id,就是stored script 的id,就是上面定义的add_asset。
脚本含义:给people索引下,id=1 的数据,资产加 100 。
3、inline script 细心的同学就会发现,文档id=2,也就是李四是2001 出生(birthday)的,创建时间2020年(当前),所以他的age应该是19才对。
1 2 3 4 5 6 7 POST http://172.16.1.236:9201/people/_doc/2/_update { "script": { "source": "ctx._source.age=19" } }
四、painless 语言的一些例子 先讲一些常用的吧
1、给已有的文档添加新字段 需求:比如我们现在想加一个 “hobby”(爱好) 和 “sex”(性别)的字段,并赋值。
1 2 3 4 5 6 7 POST http://172.16.1.236:9201/people/_update_by_query { "script": { "lang": "painless", "source": "if (ctx._source.hobby == null) {ctx._source.hobby= ['看电影','听音乐','搬砖']} if (ctx._source.sex == null) {ctx._source.sex= '男'} " } }
以上添加字段hobby,并赋值一个字符串数组:['看电影','听音乐','搬砖'],同时也添加 sex字段,值为男
2、移除数组字段某一项 现在需求又改了,id=1 张三这个人不喜欢 搬砖 这个爱好,要把它移除掉.
1 2 3 4 5 6 7 8 9 10 POST http://172.16.1.236:9201/people/_doc/1/_update { "script": { "lang": "painless", "source": "if (ctx._source.hobby.contains(params.hobbyName)) {ctx._source.hobby.remove(ctx._source.hobby.indexOf(params.hobbyName))} ", "params":{ "hobbyName":"搬砖" } } }
先判断数组是否包含hobbyName这个内容,包含则通过数组索引进行删除。还有其他写法如下:
1 2 3 4 5 6 7 8 9 10 POST http://172.16.1.236:9201/people/_doc/1/_update { "script": { "lang": "painless", "source": "ctx._source.hobby.removeIf(it -> it == params.hobbyName);", "params":{ "hobbyName":"搬砖" } } }
还有一种简单粗暴,直接全部替换覆盖 ٩(๑❛ᴗ❛๑)۶
3、自定义返回脚本字段 例子1:自定义脚本字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 POST http://172.16.1.236:9201/people/_search { "script_fields":{ "year-asset":{ "script":{ "lang":"painless", "source":"doc['asset'].value * params.value", "params":{ "value":12 } } } } }
自定义字段year-asset代表每个人的年薪,这个字段是随意定义的。
查询结果返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 { "took": 9, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 4, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "people", "_type": "_doc", "_id": "3", "_score": 1.0, "fields": { "year-asset": [ 46656.0 ] } }, { "_index": "people", "_type": "_doc", "_id": "4", "_score": 1.0, "fields": { "year-asset": [ 226656.0 ] } }, { "_index": "people", "_type": "_doc", "_id": "2", "_score": 1.0, "fields": { "year-asset": [ 24010.56 ] } }, { "_index": "people", "_type": "_doc", "_id": "1", "_score": 1.0, "fields": { "year-asset": [ 22810.56 ] } } ] } }
发现返回的只有我们定义的字段,其他的属性没有返回,可以加个参数_source。
例子2:结果集返回fields与_source数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 POST http://172.16.1.236:9201/people/_search { "query": { "match": { "name":"李四" } }, "_source": { "includes": [], "excludes": ["update_time"] }, "script_fields":{ "year-asset":{ "script":{ "lang":"painless", "source":"doc['asset'].value * params.value", "params":{ "value":12 } } } } }
_source 下面有两个属性:includes、excludes。
includes 表示返回哪些字段,如果为空就返回所有
excludes 表示哪些字段不需要返回
而query 也就是查询了,可以不要,我这里是只查询李四的。数据结果返回如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 { "took": 8, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.6931471, "hits": [ { "_index": "people", "_type": "_doc", "_id": "2", "_score": 0.6931471, "_source": { "birthday": "2001-10-13", "create_time": "2020-10-13 09:52:59", "sex": "男", "name": "李四", "id": 2, "asset": 2000.88, "job": "打工仔", "age": 19, "info": "不要站在你的角度看我我怕你看不懂!!!", "hobby": [ "看电影", "听音乐" ] }, "fields": { "year-asset": [ 24010.56 ] } } ] } }
发现定义_source 就返回想要的数据了。
例子3:自定义多个脚本字段 在加一个birthday-year 自定义字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 POST http://172.16.1.236:9201/people/_search { "query":{ "match":{ "name":"赵六" } }, "script_fields":{ "year-asset":{ "script":{ "lang":"painless", "source":"doc['asset'].value*params.value", "params":{ "value":12 } } }, "birthday-year":{ "script":{ "lang":"painless", "source":"doc.birthday.value.year" } } } }
这里多加了一个birthday-year只返回birthday的年份。
结果返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 { "took": 8, "timed_out": false, "_shards": { "total": 3, "successful": 3, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1.2039728, "hits": [ { "_index": "people", "_type": "_doc", "_id": "4", "_score": 1.2039728, "fields": { "year-asset": [ 226656.0 ], "birthday-year": [ 1993 ] } } ] } }
4、自定义脚本排序 有些时候需要一些复杂规则的排序就需要使用脚本来实现。如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 POST http://172.16.1.236:9201/people/_search { "query": { "match_all": { } }, "sort": { "_script":{ "type":"number", "order":"desc", "script":{ "lang":"painless", "source":"doc['asset'].value * doc['age'].value" } } } }
上面的例子在实际中是没什么意义的,这里只是举个例子而已。就是查询所有数据,结果以 资产和年龄相乘 降序返回
5、简单更新字段 1 2 3 4 5 6 7 8 9 10 11 POST http://172.16.1.236:9201/people/_doc/1/_update { "script":{ "lang":"painless", "source":"ctx._source.birthday=params.newBirthday;ctx._source.age=params.newAge", "params":{ "newBirthday":"1999-09-20", "newAge":21 } } }
修改id=1 的生日改为1999年,年龄改为21。
6、带判断的脚本更新 1 2 3 4 5 6 7 8 9 10 POST http://172.16.1.236:9201/people/_doc/1/_update { "script":{ "lang":"painless", "source":"if(ctx._source.asset < 30000){ctx._source.asset += params.add}", "params":{ "add":1000 } } }
过年回来,给优秀员工(id=1) 加1000 工资(只有当他的工资不高于30000时成立)。
7、Lambda 表达式 1 2 3 4 5 list.removeIf(item -> item == 2); list.removeIf((int item) -> item == 2); list.removeIf((int item) -> { item == 2 }); list.sort((x, y) -> x - y); list.sort(Integer::compare);
脚本也支持lambda表达式,上面有用过。
8、查询脚本过滤 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 POST http://172.16.1.236:9201/people/_search { "query": { "bool": { "filter": { "script": { "script": { "lang": "painless", "source": "doc['age'].value > 25" } } } } } }
只查询年龄大于25的
9、更多 实际开发不只这些,日期操作,定义脚本方法等等更多语法可参考,官方文档:《painless语法指南》
具体的Java api 调用可以看,下面这个Script类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package org.elasticsearch.script;public final class Script implements ToXContentObject , Writeable { public Script (String idOrCode) { this (DEFAULT_SCRIPT_TYPE, DEFAULT_SCRIPT_LANG, idOrCode, Collections.emptyMap(), Collections.emptyMap()); } public Script (ScriptType type, String lang, String idOrCode, Map<String, Object> params) { this (type, lang, idOrCode, type == ScriptType.INLINE ? Collections.emptyMap() : null , params); } public Script (ScriptType type, String lang, String idOrCode, Map<String, String> options, Map<String, Object> params) { } }
注意观察就会发现,它的构造方法对应上面的脚本格式 new UpdateRequest(indexName,id).script(new Script(...));
五、、Lucene expressions语言的一些表达式 只列举一些表达式
1、数值字段表达式 1 2 3 4 5 6 7 8 doc['field_name' ].value doc['field_name' ].empty doc['field_name' ].length doc['field_name' ].min () doc['field_name' ].max () doc['field_name' ].median () doc['field_name' ].avg () doc['field_name' ].sum ()
当文档完全缺少该字段时,默认情况下该值将被视为0。您可以将其视为另一个值,例如doc['myfield'].empty ? 100 : doc['myfield'].value。
2、日期字段表达式 日期字段被视为自1970年1月1日以来的毫秒数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 doc['field_name'].date.centuryOfEra // 世纪(1-2920000) doc['field_name'].date.dayOfMonth // 第一天(1-31),例如1每月的第一天。 doc['field_name'].date.dayOfWeek // 星期几(1-7),例如1星期一。 doc['field_name'].date.dayOfYear // 一年中的一天,例如11月1日。 doc['field_name'].date.era // 时代:0公元前,1公元前。 doc['field_name'].date.hourOfDay // 小时(0-23)。 doc['field_name'].date.millisOfDay // 一天中的毫秒数(0-86399999)。 doc['field_name'].date.millisOfSecond // 秒内的毫秒数(0-999)。 doc['field_name'].date.minuteOfDay // 在一天中的分钟(0-1439)。 doc['field_name'].date.minuteOfHour // 一小时内的分钟(0-59)。 doc['field_name'].date.monthOfYear // 一年中的月份(1-12),例如1一月。 doc['field_name'].date.secondOfDay // 一天中的第二个(0-86399)。 doc['field_name'].date.secondOfMinute // 分钟内(0-59)秒。 doc['field_name'].date.year // 年(-292000000-292000000)。 doc['field_name'].date.yearOfCentury // 本世纪内的年份(1-100)。 doc['field_name'].date.yearOfEra // 时代以内(1-292000000)。
3、geo_point类型表达式 1 2 3 doc['field_name'].empty //一个布尔值,指示该字段在doc中是否没有值。 doc['field_name'].lat //地理位置的纬度。 doc['field_name'].lon //地理位置的经度。
六、参考链接